
Introduction
To build even the simplest machine learning models, a solid grasp of basic linear algebra can make a world of difference in understanding why models are designed the way they are. Such knowledge becomes even more crucial when working with more advanced machine learning models. While many coding libraries and frameworks allow you to run sophisticated AI models out of the box, if you don’t understand the underlying mathematics you can end up applying a model in the wrong context, or be limited in your ability to optimize or troubleshoot the model effectively.
Broadly, linear algebra is the study of linear equations, i.e. equations in which the highest power of the variable is one. However, linear algebra is also the branch of mathematics that deals with operations on multi-dimensional data, enabling us to translate geometric concepts of dimension into concrete calculations. In this article I’ll use linear algebra to focus on multidimensional mathematical objects, such as vectors and matrices, and discuss the operations we apply to them in the context of machine learning algorithms.
Thus, this article considers how linear algebra is applied in deep learning, and how data is structured and manipulated in deep learning frameworks such as NumPy, PyTorch, and TensorFlow. While linear algebra covers an extensive range of topics, we will focus here on concepts that help us understand and work effectively with deep learning.
Definitions
Scalars
Scalars are just a single number without any associated dimension, and are used for counting or to represent a magnitude.
- In expressions they are denoted with lowercase, italic typeface letters:
, , , , etc. And in code we usually give scalars lowercase variable names. - We use
to refer to the set of scalar real numbers i.e. to define the space of all (continuous) real-valued scalars. - Hence the expression
is the formal way of stating that is a real-valued scalar. For example .
When we introduce them, we specify what the data type is and/or what kind of number they are, for example:
“let
“let
In PyTorch, scalars are implemented as tensors (a linear algebra object we’ll come to later) that contain only one element. In TensorFlow, scalars are implemented as a constant, creating a constant tensor from a tensor-like object; a 0-dimensional tensor that holds a single value.
| Implemented as Tensors that contain only one element | |
|---|---|
| PyTorch | TensorFlow |
|
|
Vectors
A vector is a one-dimensional (1D) array of numbers - a fixed-length array of scalars where each scalar is referred to as an “element” of the vector. Alternative terms for “elements” that are often used in the literature include “indicies”, “entries” and “components”.
In physics, vectors often represent dimensions and associated coordinate axes in space. For example, some point
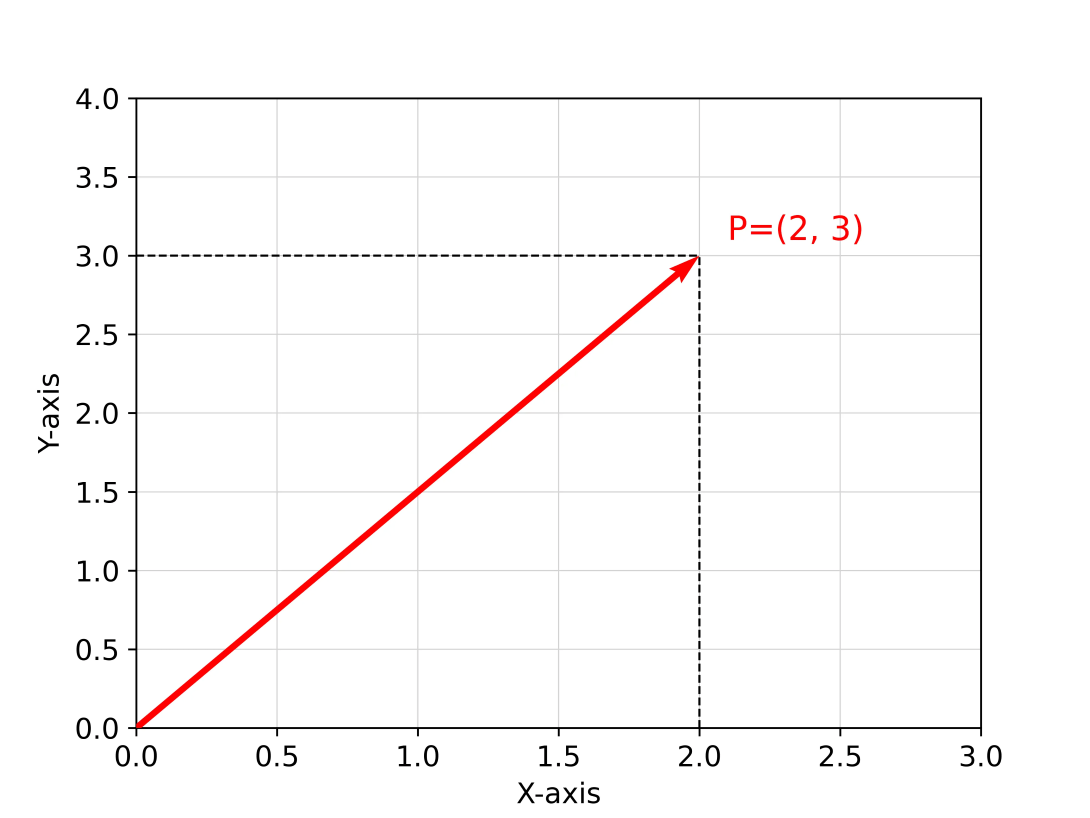 | 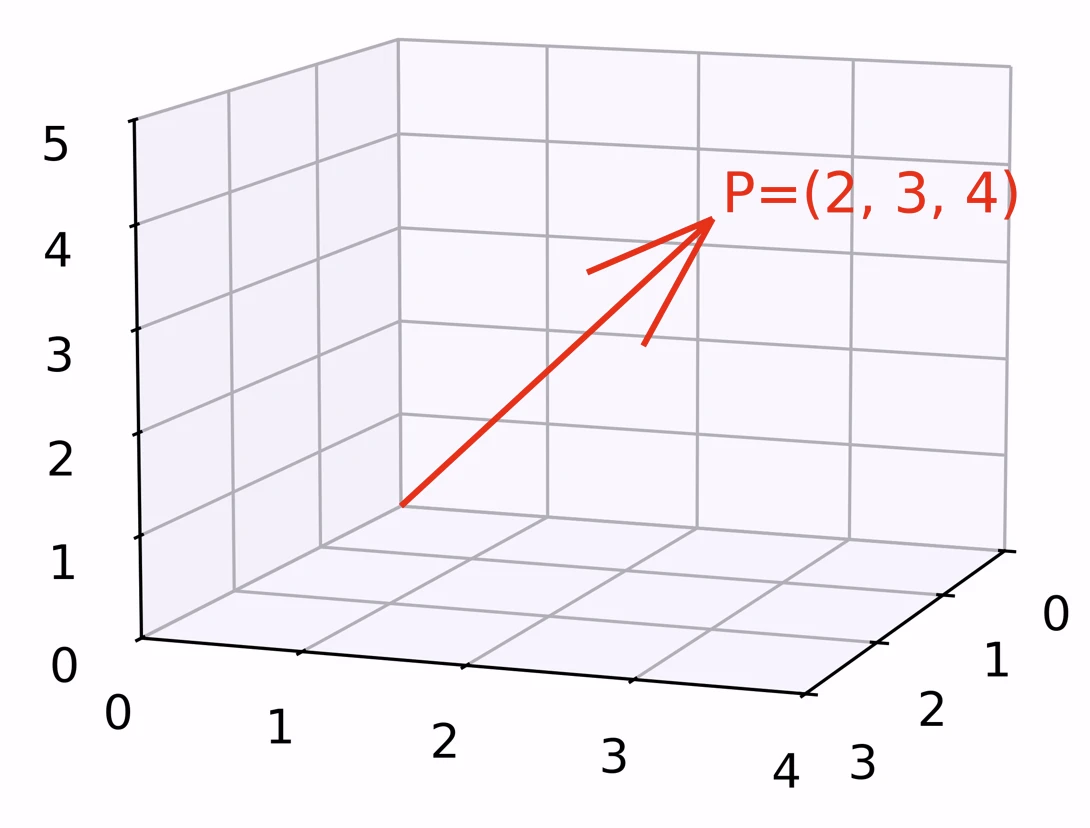 |
|---|
Illustration of the relationship between a point P in 2D space (left) and in 3D space (right) and its associated vector p
In mechanics, we might use vectors to represent physical quantities such as forces acting on a material point or solid, speeds, accelerations, moments of force, etc. Here, a vector contains the measure of the magnitude or length (arithmetic element) to which the direction (geometric element) is added.
In computer science, vectors commonly represent elements in an array or list. For example, in C++, the Standard Library defines a vector class to
manage such data structures. Depending on the language, the elements of these arrays might all contain the same type of element. Alternatively the
language may allow the array to hold different types of element.
In machine learning, vectors often represent different features of a dataset and so are sometimes referred to as the feature vector.
This feature vector is a point in an abstract feature space that includes all possible inputs for a model, and so engineers
might discuss and interpret vectors in feature space almost as if they were representing some coordinate in a geometric space. For example,
clustering algorithms (e.g., k-nearest neighbors or HDBSCAN) interpret the feature vector as a coordinate in geometric space. In any event, the
feature vector locates a specific point in
- In expressions vectors are denoted with lowercase, bold, ordinary typeface letters:
, , , etc. - The convention is to represent vectors by stacking their elements vertically, which we refer to as column vector. For example:
- A shorthand is often used where vectors are represented horizontally i.e. as a row vector:
-
We use
to refer to the set of -dimensional vectors of real numbers; the -element vector that lies in the set formed by taking the Cartesian product of times, with being referred to as the dimensionality of the vector i.e. the number of elements. -
For example, a vector in
takes the shape of:
- Since it is often a little clumsy to keep writing vectors as columns, we use the transpose operator to show that they should be rotated, for example:
- Square or round brackets may be used; no distinction is given to either notation.
- Equality of vectors: two vectors are equal if they have the same magnitude and direction, they can be placed on the same or parallel lines. Equal vectors located on parallel lines are called equipollent vectors and the operation by which a vector is moved by a translation on a line parallel to the vector support is called an equipollent operation.
- If two vectors have the same magnitude but opposite directions, they are called opposite vectors and this is expressed by:
. - Two vectors that do not have the same magnitude but have the same support line direction are called collinear vectors, regardless of the direction.
- In general, vectors described in mathematics textbooks are 1-indexed - however - for many programming languages, they are 0-indexed.
| Implemented as 1st Order Tensors | ||
|---|---|---|
| Implemented as 1st Order Tensors | ||
| NumPy | PyTorch | TensorFlow |
| NumPy | ||
|
||
| PyTorch | ||
|
||
| TensorFlow | ||
|
||
|
|
|
Matrices
A matrix is a 2D array of numbers, so each element is identified by two indicies instead of just one as was the case with vectors. One of the advantages of using a matrix instead of a table is that they can be much more easily manipulated by computers in large-scale calculations.
For most practical applications, the matrix elements have specific meanings, such as the distance between cities, demographic measures such as survival probabilities (represented in a Leslie matrix) or the absence or presence of a path between nodes in a graph (represented in an adjacency matrix), which is applied in network theory (Maurits and Ćurčić-Blake, 2017).
In the machine learning context the rows of the matrix are used to represent to individual records, while the columns represent distinct features. Thus, when we considered vectors, we represented individual features as sets of scalar instances. Now, with matrices, we can represent sets of features as a collection of vector instances. In this sense, a matrix can be viewed as an ordered collection of vectors. And as we mentioned, conventionally we are referring here to collections of column vectors.
- In expressions they are denoted by uppercase, bold, ordinary typeface letters:
, , , etc. - We use
to signify that the matrix contains real-valued scalars arranged as rows and columns. More formerly this is known as the order of the matrix. - We usually identify the elements of a matrix using its name in italic but not bold font, and list the indices with separating commas. For example,
is the upper left entry of and is the bottom right entry. For example:
- We can identify all the numbers with vertical coordinate
by writing a " " for the horizontal coordinate. For example, denotes the horizontal cross section of with vertical coordinate . This is known as the -th row of . Likewise, is the -th column of . Thus, for example, the matrix shown above can be represented as:
- As was the case with vectors, square or round brackets may be used; no distinction is given to either notation.
- Likewise, matrices described in mathematics textbooks are 1-indexed - however - for many programming languages, they are 0-indexed. In Python, this means that a matrix can be
thought of as a list of sublists in which each sublist is of the same length. Of course, this is exactly how we defined
to begin with. - We can think of vectors as matrices with a single row or column. A column vector with three elements is a
matrix: it has three rows and one column. Similarly, a row vector of four elements acts like a matrix: it has one row and four columns. - And finally, matrices of different sizes may by convention be given specific names, for example:
- Square matrix: a matrix where the number of rows is equal to the number of columns is called a square matrix, and is often denoted
. If the number of rows and columns is equal to , then we say the matrix is of size . - Symmetric matrix: a matrix whose elements have the property
is called a symmetric matrix. Elements of the matrix are symmetrical with respect to the first diagonal. - Skew-symmetric matrix: a matrix whose elements have the property
is called a skew-symmetric (antisymmetric or antimetric) matrix. If then the definition becomes: or so the elements on the main diagonal of an antisymmetric matrix are zero. - Diagonal matrix: a matrix with non-zero elements only on the main diagonal is called a diagonal matrix. The definition of a diagonal matrix is:
if and if . - Triangular matrix: a matrix that has nonzero elements on the diagonal and above or below is called a triangular matrix. A matrix is an upper triangular matrix if the elements below the main diagonal are zero and a lower triangular matrix if the elements above the main diagonal are zero.
- Square matrix: a matrix where the number of rows is equal to the number of columns is called a square matrix, and is often denoted
| Implemented as 2nd Order Tensors | ||
|---|---|---|
| Implemented as 2nd Order Tensors | ||
| NumPy | PyTorch | TensorFlow |
| NumPy | ||
|
||
| PyTorch | ||
|
||
| TensorFlow | ||
|
||
|
|
|
Tensors
Hopefully by now you will have seen a pattern developing: a scalar has no dimensions, a vector has one, and a matrix has two. Thus, a mathematical object with more than two dimensions is colloquially referred to as a tensor.
The number of dimensions a tensor has defines its order, which is not to be confused with the order of a matrix. A 3D tensor has order 3. A matrix is a tensor of order 2. A vector is an order-1 tensor, and a scalar is an order-0 tensor. And so in most general case, any array of numbers arranged on a regular grid with a variable number of axes can be referred to as a tensor.
- In expressions they are denoted with uppercase, sans-serif typeface letters:
, , , etc.
| Implemented as nth Order Tensors | ||
|---|---|---|
| Implemented as nth Order Tensors | ||
| NumPy | PyTorch | TensorFlow |
| NumPy | ||
|
||
| PyTorch | ||
|
||
| TensorFlow | ||
|
||
|
|
|
It isn’t immediately intuitive to think about geometric spaces with dimensions larger than 3. Indeed this is one of the reasons I felt this article was necessary so that we can put our faith in mathematical rigour and not have to rely on mental models. Nonetheless, in machine learning the example that springs to mind is the representation of a colour image. Usually the three colour channels of red, green, and blue are used to create a full colour image. Each of these individual colour channels is represented by a matrix, where each element is known as a pixel. The matrix of pixels maps directly to the 2D representation of geometric space being photographed, and so when we combine the three colour channels together in a single mathematical object we create a tensor of order 3.
As an aside, you’ll notice then that tensors from order 3 and above don’t have standardized names.
| Order | Tensor name | Geometric name |
|---|---|---|
| 0 | Scalar | Point |
| 1 | Vector | Line |
| 2 | Matrix | Plane |
| 3 | Tensor | Volume |
Selected Mathematics of Linear Algebra
Vector Operations
All common mathematical operations, such as addition, subtraction and multiplication, can be executed on vectors, just as they can be executed on e.g. real numbers (Maurits and Ćurčić-Blake, 2017). The extension of these basic operations to vectors is done in such a way that important properties of the basic mathematical operations (such as commutativity, associativity and distributivity) are preserved as far as possible.
Vector-Vector Addition and Subtraction
Vector-vector addition and subtraction are element-wise operations, defined only for vectors of the same size (i.e., number of elements). These operations of vector arithmetic accomplish useful geometric transformations, often creating new vectors.
Consider two vectors of the same size, we have the following:
And so, for example, the addition of
Essentially then, all we do is add (or subtract) the respective coordinates to get the new vector that results. In Python we can achieve this with a simple one-line implementation:
def add(v1, v2):
return (v1[0] + v2[0], v1[1] + v2[1])Since we can interpret vectors as arrows or as points in the plane, we can visualize the result of the addition in both ways. Consider the example of
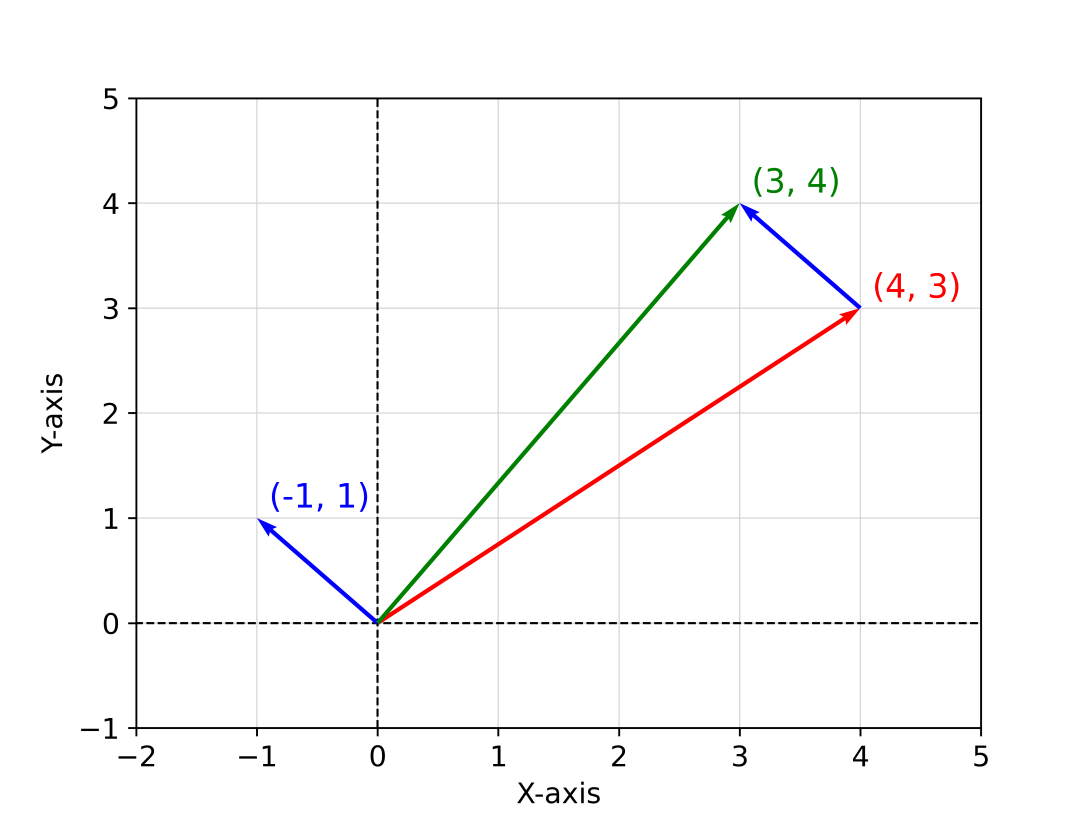 Interpretation of vectors as both arrows and as points in a plane.
Interpretation of vectors as both arrows and as points in a plane.
Geometrically, the addition of two vectors (say,
Vector addition and subtraction have a series of fundamental properties worth mentioning:
- Commutativity:
. - Associativity:
. - Vector addition is distributive over the multiplication with a scalar:
. Thus, multiplying a scalar by the sum of two vectors results in the same vector as multiplying the scalar by each vector individually and then adding the results. - From the definition of vector subtraction it follows that there must be a zero vector, i.e. the result of subtracting a vector from itself
. This is the only vector that has zero magnitude. For vectors to have a null sum, the polygon built with them must be closed. In particular, in the case of three vectors, the condition that they have a null sum is that, by placing each vector with the origin at the end of the previous one, a triangle is formed. And so, since the triangle is a plane figure, the three vectors must be coplanar. - Adding the zero vector has no effect:
the zero vector here being the same size as vector but where each element is . - Substracting a vector from itself returns the zero vector:
. - Vector addition and subtraction has the effect of moving, or translating, or displacing an exisiting point or collection of points.
Vector-Scalar Multiplication
Vector-scalar multiplication is an element-wise operation. Suppose we represent the scalar term as
The word scalar is clearly the appropriate term given the effect of this operation is to scale the target vector by the given factor. In turn note how
the product of a vector
Notice also how each vector component is also scaled by the same scalar term, while the aspect ratio remains unchanged.
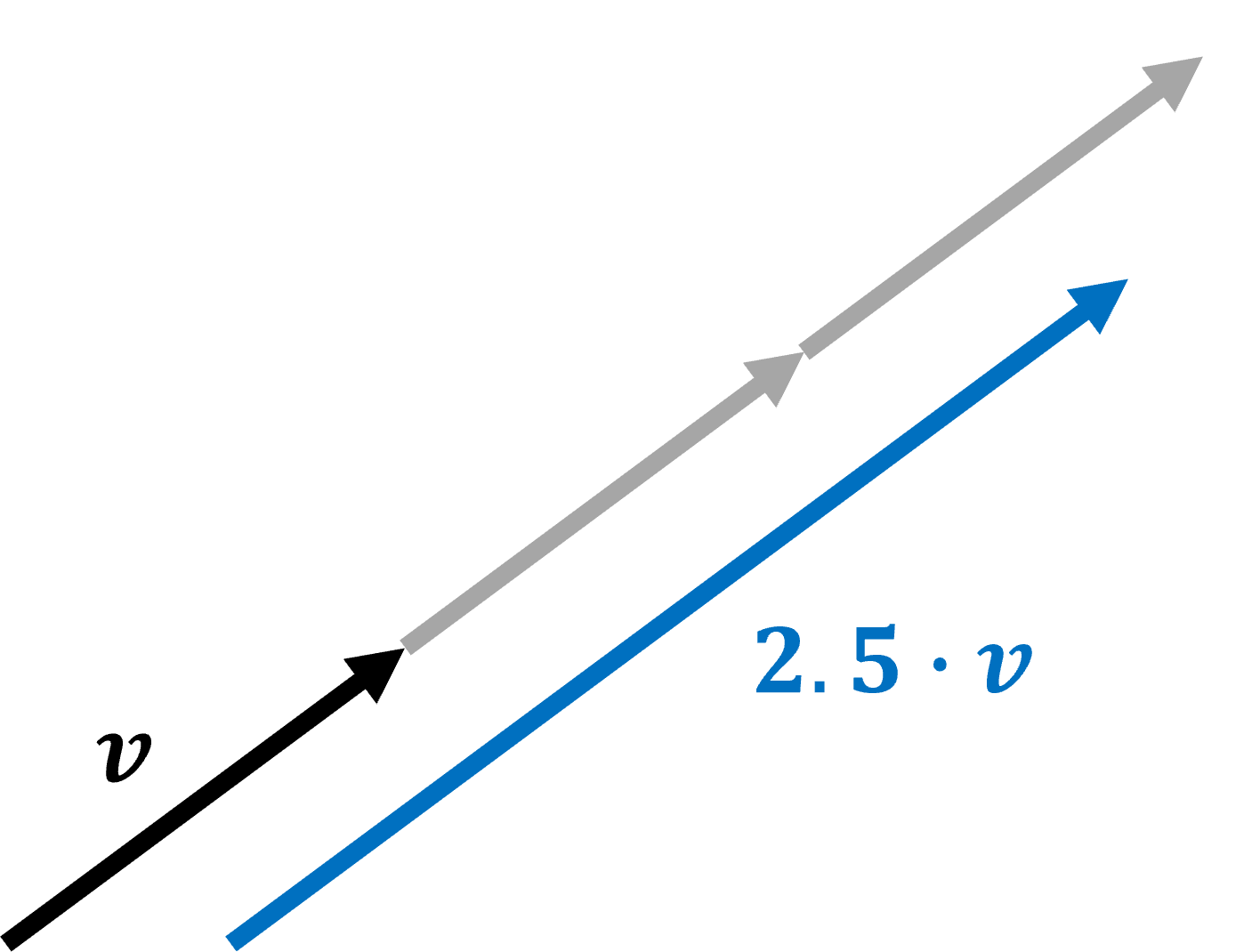
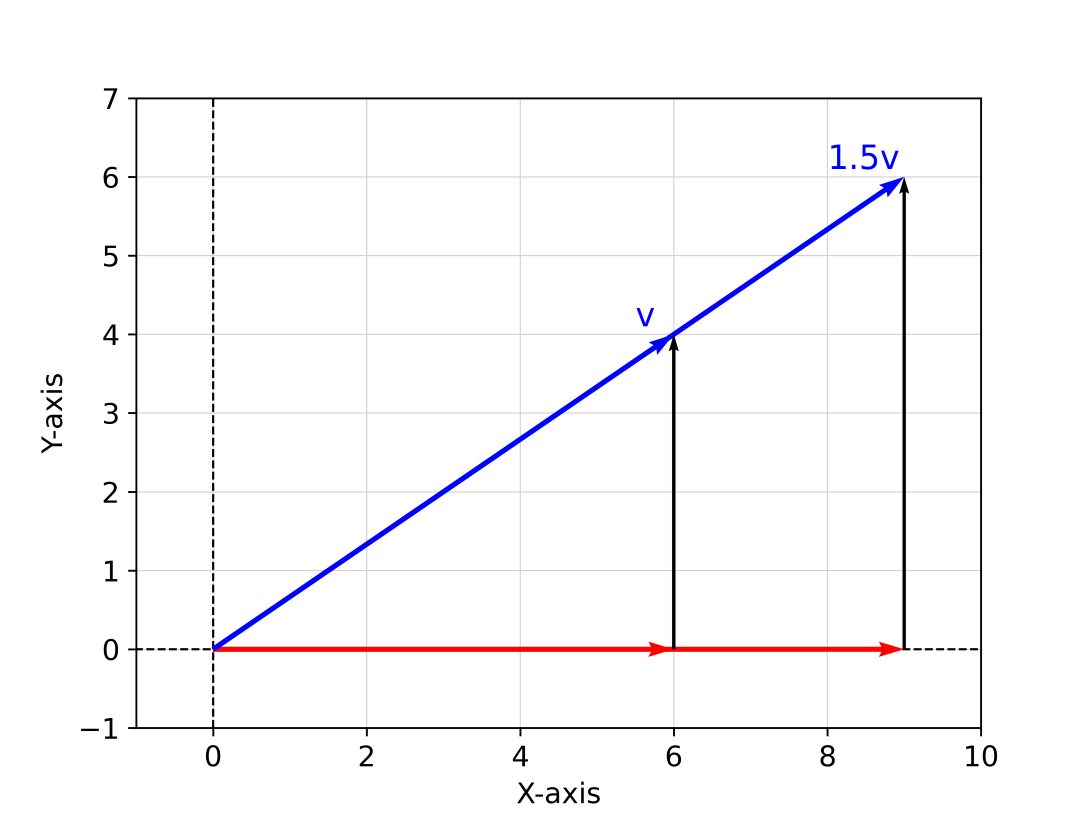
Geometric explanation of scalar multiplication of a vector.
Vector-scalar multiplication satisfies a series of important properties:
- Associativity:
- Left-distributive property:
- Right-distributive property:
- Right-distributive property for vector addition:
Linear Combinations of Vectors
In linear algebra, vector addition and scalar multiplication are the two operations that define a vector space. By combining these, we can create linear combinations, which form the foundation for many concepts in linear algebra.
You might also see linear combinations represented in the literature using the summation notation. For example, we can build a linear combination
from a set of
Here the scalars
Linear combinations are perhaps the most fundamental operation in linear algebra; nearly every concept in the field builds upon this operation. For example, linear-regression (see below) is a linear combination of vectors.
Vector-Vector Multiplication - Dot Product
One kind of multiplication we have already seen for vectors is scalar multiplication; combining a scalar (a real number) and a vector to get a new vector. It turns out that there are two important ways you can multiply a vector with another vector; the dot product and the cross product. Let’s consider the dot product or inner product first.
Given two vectors, each of dimension
Note the following points:
- the
superscript, which we briefly introduced above is used to denote the transpose of the vector. For example becomes . - we introduce the summation notation,
, as the dot product reduces to the summation of the individual components of the two vectors being multiplied together.
After normalizing two vectors to have unit length, the dot product expresses the cosine of the angle between them. That is to say, the scalar product can be used to resolve (project) one vector along the direction of another.
And it should be noted that both methods given above for finding the dot product of two vectors are entirely equivalent and will return the same value.
Vector-Vector Multiplication - Cross Product
We studied the dot product form of vector-vector multiplication in the previous section - it resulted in a single scalar value. Now lets consider the other form - the cross product. Here, the product of two vectors results in a third vector. Sure enough, an alternative name for the cross product, found in the literature, is the vector product, exactly because it results in a vector.
For two vectors
the cross product is defined as:
The cross product is not commutative, i.e.
Norms
Measuring vectors is an important operation in machine learning applications. Intuitively, we think about the length of a vector as the distance between its “origin” and its “end”. And in mathematics this is referred to as the norm or magnitude.
Norms “map” vectors to non-negative values. In this sense norms are also functions that assign length
Formerly:
More rigorously, a norm is any function
- Positive definite:
. Meaning, the length of any vector has to be a positive value (i.e., a vector can’t have negative length), and a length of 0 occurs only for the zero vector . - The triangle inequality:
. Meaning, for any triangle the sum of any two sides must be greater or equal to the length of the third side. - Homogeneous:
, . Meaning, for all real-valued scalars, the norm scales proportionally with the value of the scalar.
Euclidean
With
Manhatten
With
It is defined as:
The
Matrix Operations
All common mathematical operations, such as addition, subtraction and multiplication, can be executed on matrices, very similar to how they are executed on vectors.
Matrix-Matrix Addition and Subtraction
Matrix addition and subtraction are quite straightforward generalizations of the same operations on vectors. Thus assuming the matrices we are performing these operations on have the same shape, we can calculate their addition or subtraction in element-wise fashion.
For example, the sum
And the subtraction of
Don’t forget that both matrix addition and subtraction can result in the zero, or null, matrix, where all elements are zero.
- Matrix addition is commutative:
. - Matrix addition is associative:
. - The distributive law holds for matrix addition:
.
Matrix-Scalar Multiplication
As was the case with matrix addition and subtraction, scalar multiplication is also a straightforward generalization of the same operation on vectors.
For a scalar
Matrix-Vector Multiplication
Matrix-vector multiplication is the equivalent of taking the dot product of each column
It is defined as:
There are two fundamentally different yet equivalent ways to interpret the matrix-vector product:
-
In the column point of view, the multiplication of the matrix
by the vector produces a linear combination of the columns of the matrix: , where and are the first and second columns of the matrix . -
In the row point of view, multiplication of the matrix
by the vector produces a column vector with coefficients equal to the dot products of rows of the matrix with the vector .
Matrix-Matrix Multiplication
The matrix-vector product discussed above is an important special case of the more general matrix-matrix product.
The matrix product of matrices
And this operation is equivalent to:
“The element in the
Notice how this bears a close relationship with the dot product form of vector-vector multiplication, that we introduced above. You can also see how multiplying two
matrices involves repeated vector inner product calculations, for example, suppose matrix
Some additional rules of matrix-matrix multiplication include:
- Two matrices may not commute i.e. in general
. - The associative law always holds i.e. for matrices which can be multiplied,
. - The general principle to ensure the associative law holds is to keep the left to right order of the multiplication. But within that limitation any two adjacent matrices can be multiplied.
The Hadamard Product
Note that the standard product of two matrices, as introduced above, is not simply a matrix containing the product of the individual elements. If you wanted to do this (less common) operation you require the Hadamard product (Schur product), or element-wise product.
This form of matrix multiplication requires that the two matrices involved are the same size.
The Hadamard product is defined as follows:
Perhaps you can see how the Hadamard product also represents the scalar multiple of a matrix, e.g.
The Transpose of a Matrix
We briefly introduce the transpose operation when discussing vectors, and the convenience of representing column vectors as row vectors (and vice-versa). Of course, it is just as common to use the transpose operation with respect to matrices, given the familial relationship between vectors and matrices.
The transpose of a matrix
The resulting matrix is called the transposed matrix of
If
When the transpose of a matrix is equal to the original matrix i.e.
Additional properties of transposed matrices include:
Matrix Determinant
The determinant of a matrix is a single number that indicates whether a matrix is invertible or whether it is singular, which in turn determines whether the columns of the matrix are linearly independent or not and thus whether the system of linear equations formed by the matrix has a unique solution or not.
In the
In the general
Where
Notice how, for convenience, we used the notation
Often, especially with determinants of large order, we can simplify the evaluation rules - aided by the following properties of determinants:
- For a square matrix
, a determinant equal to implies the matrix is singular (i.e. noninvertible), whereas a determinant equal to implies the matrix is not singular (i.e. invertible). - If two rows (or two columns) of a determinant are interchanged then then value of the determinant is multiplied by
. - For example,
. - But, if we interchange the columns,
. - Likewise, if we interchange the rows,
.
- For example,
- The determinant of a matrix
and the determinant of its transpose are equal. - For example
.
- For example
- If two rows (or two columns) of a matrix
are equal then it has zero determinant. For example:
-
If the elements of one row (or one column) of a determinant are multiplied by some scalar, say
, then the resulting determinant is times the given determinant. For example: - Note the exception here is when one row (or one column) of the determinant is a multiple of another row (or column). In which case the determinant will be zero.
-
If we add (or subtract) a multiple of one row (or column) to another, the value of the determinant will be unchanged:
Given
add row 1 to row 2, gives: -
The determinant of a lower triangular matrix, an upper triangular matrix, or a diagonal matrix is the product of the elements on the leading diagonal.
The Inverse Matrix and Identity Matrix
The Identity Matrix
The identity matrix (or unit matrix), denoted
For example:
The identity matrix plays the same role in matrix multiplication as the number
The Inverse Matrix
Just as any real, non-zero number
Given an
Where
There are three important points to note here:
- Non-square matrices do not have inverses.
- The inverse of
is usually written . - Not all square matrices have inverses.
Regarding the final point made just above, consider the following example:
What the above example shows us is that matrix
Let’s consider the following points of note:
-
If a matrix does have an inverse, then that inverse is unique. For example, suppose
and are both inverses of . Then, by definition of the inverse, and . - Now consider the two ways of forming the product
: - And hence
and the inverse is unique.
- Now consider the two ways of forming the product
-
There is no such operation as division in matrix algebra:
- Instead of
we write or depending on the order required.
- Instead of
-
Assuming that the square matrix
has an inverse , then the solution of the system of equations is found by pre-multiplying both sides by . For example: - Given:
- Pre-multiply by
gives:
- Using associativity:
- Then, using
, gives us:
- And thus:
-
Finally, let’s connect our discussion about matrix determinants with this sections introduction of singular and non-singular matrices. If a matrix has zero determinant i.e. it’s determinant is
, then that matrix is singular, which we now know to also mean it has no inverse. Conversely, where the determinant of the matrix is not zero, that matrix is non-singular and thus has an inverse. - For square matrix
:
- For square matrix
Eigenvectors and Eigenvalues
Opening Statements
A mathematical concept that relies heavily on the linear algebra we’ve discussed above, and which plays a major part in matrix calculations (such as matrix decomposition) as well as machine learning algorithms (such as principal component analysis), is that of eigenvectors and eigenvalues.
An eigenvector
where
Basic Results from Linear Algebra
Recall our assertions in the previous section regarding matrix singularity and invertibility:
- Any non-singular
matrix , for which , possesses an inverse . - A singular matrix does not possess an inverse.
Next, consider the system of equations represented by
- The system is consistent and has a unique solution for
. - The system is consistent and has an infinite number of solutions for
. - The system is inconsistent and has no solution for
.
- For case 1, consider that
. In this case, exists and the unique solution to is . - For case 2, consider that
. In this case, does not exist: - If
the system has no solutions. - If
the system has an infinite number of solutions.
- If
General Eigenvalue Problems
We are interested in systems of linear equations of the form:
Where, as mentioned already,
Firstly, we immediately notice the obvious solution for
Next, we rearrange the eigenvalue problem into the following:
We’ve already discussed how this equation has a solution if and only if the determinant of
This equation is referred to as the characteristic equation of the eigenvalue problem. It only involves one unknown,
Once the eigenvalues are known, the related eigenvectors can be found by solving for
Let’s understand eigenvectors and eigenvalues better with a specific example:
Find the eigenvalues of the matrix
- First, determine the characteristic equation as the determinant:
Examples of the use of Linear Algebra in Machine Learning
Having covered a lot of ground in introducing and discussing linear algebra it’s about time we actually relate this to real world applications. That is to say, how the mathematics of linear algebra is actually applied in data analysis and machine learning.
Linear Regression
We start with the mathematics of linear regression, one of the oldest tools in the machine learning practioners toolkit. Its roots can be traced back to the early 19th century through the work of statisticians such as Legendre and Gauss. But don’t let its age distract you, this algorithm remains fundamental to modern data analysis and machine learning. In particular its simplicity and effectiveness make it a cornerstone for understanding the broader landscape of machine learning models.
Fundamentally linear regression (LR) lets us model the relationship between one or many independent variables and a dependent variable. The term “regression” implies the dependent variable is continuous. Consider the first plot below, which shows an example dataset. Our aim with LR is to fit a straight line to this dataset - specifically to find the best fitting line, which from a high level point of view is the line that sits closest to the data.
From elementary mathematics we know of course that the basic equation for a line is
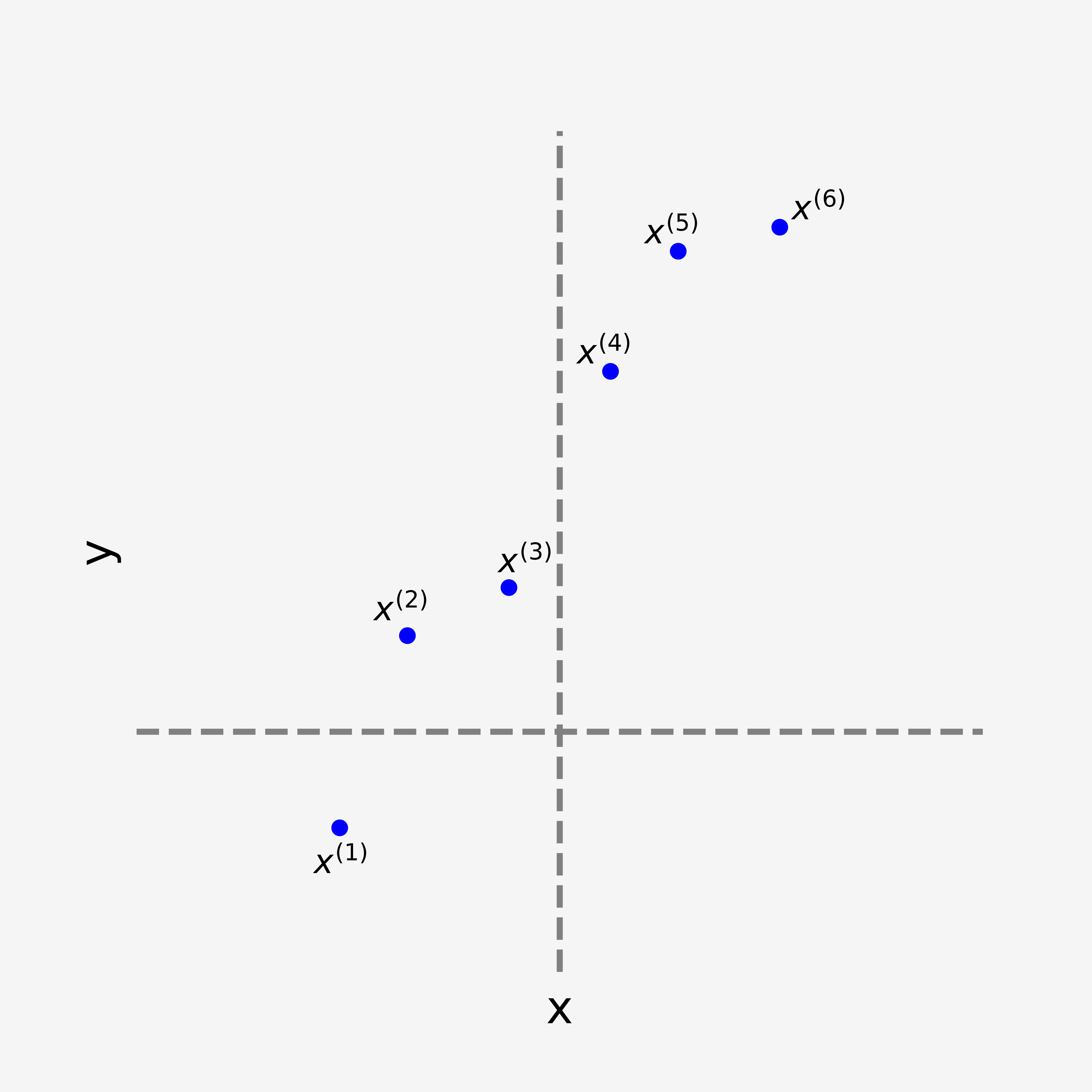
Now consider the collection of four plots shown below. Here we experiment with different values for
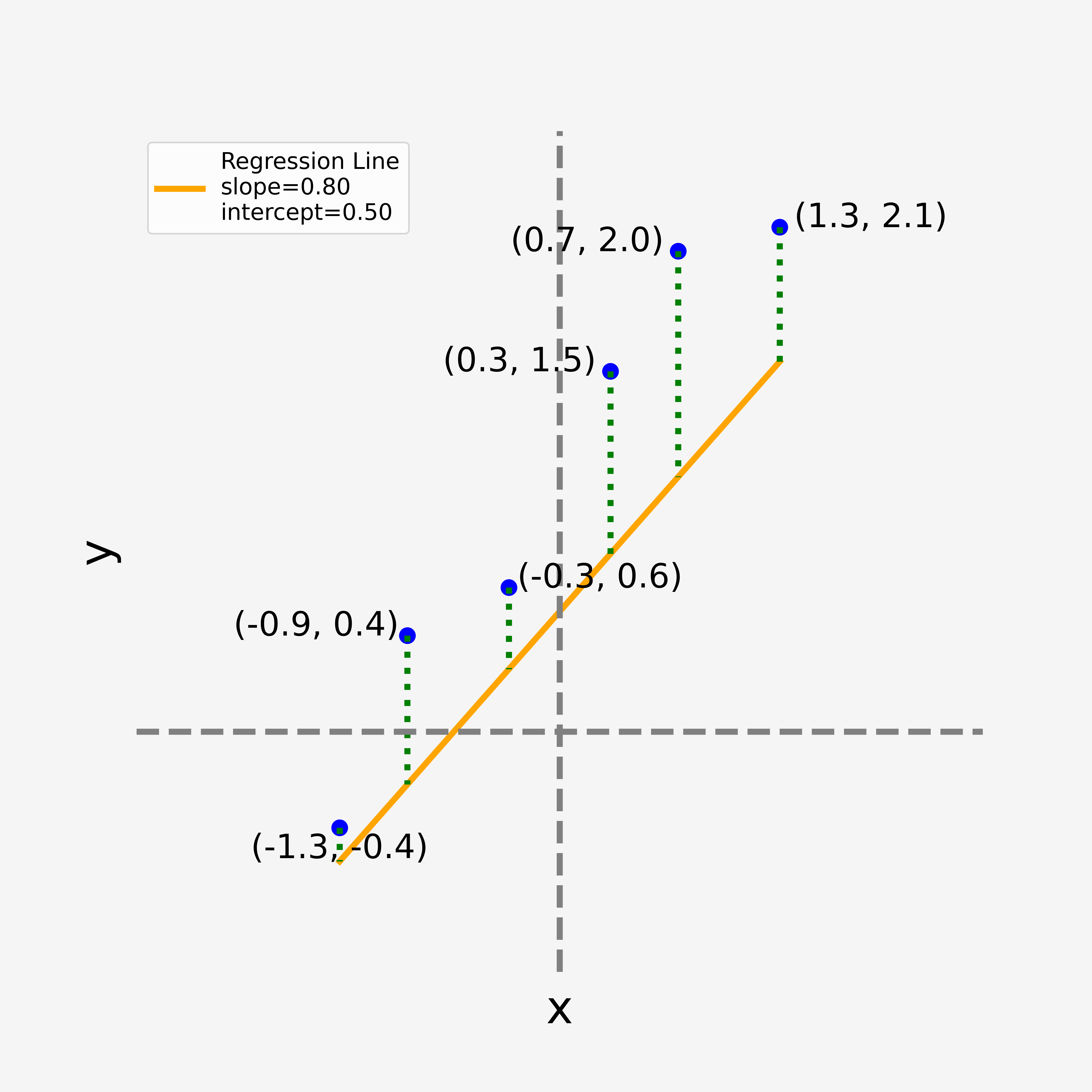
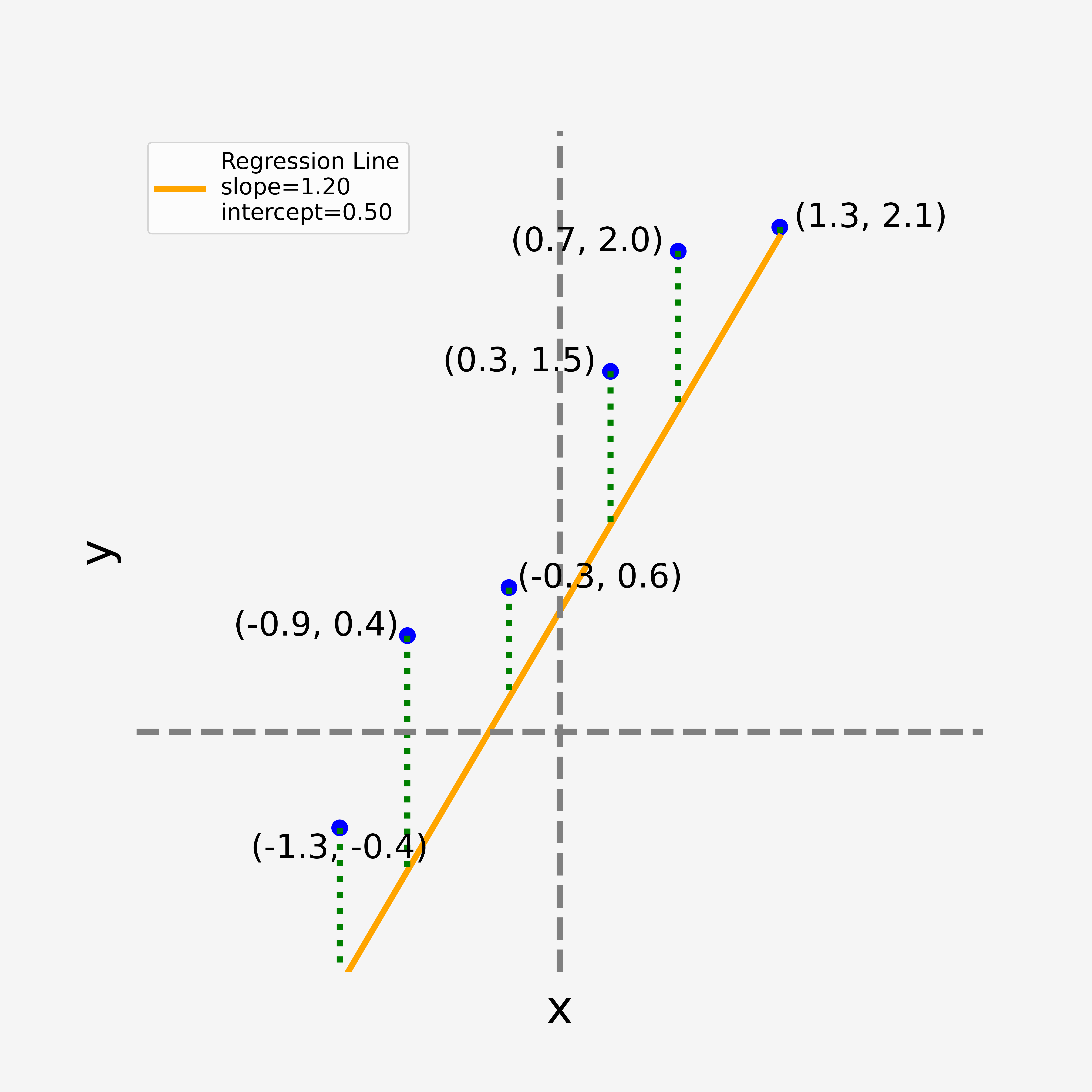
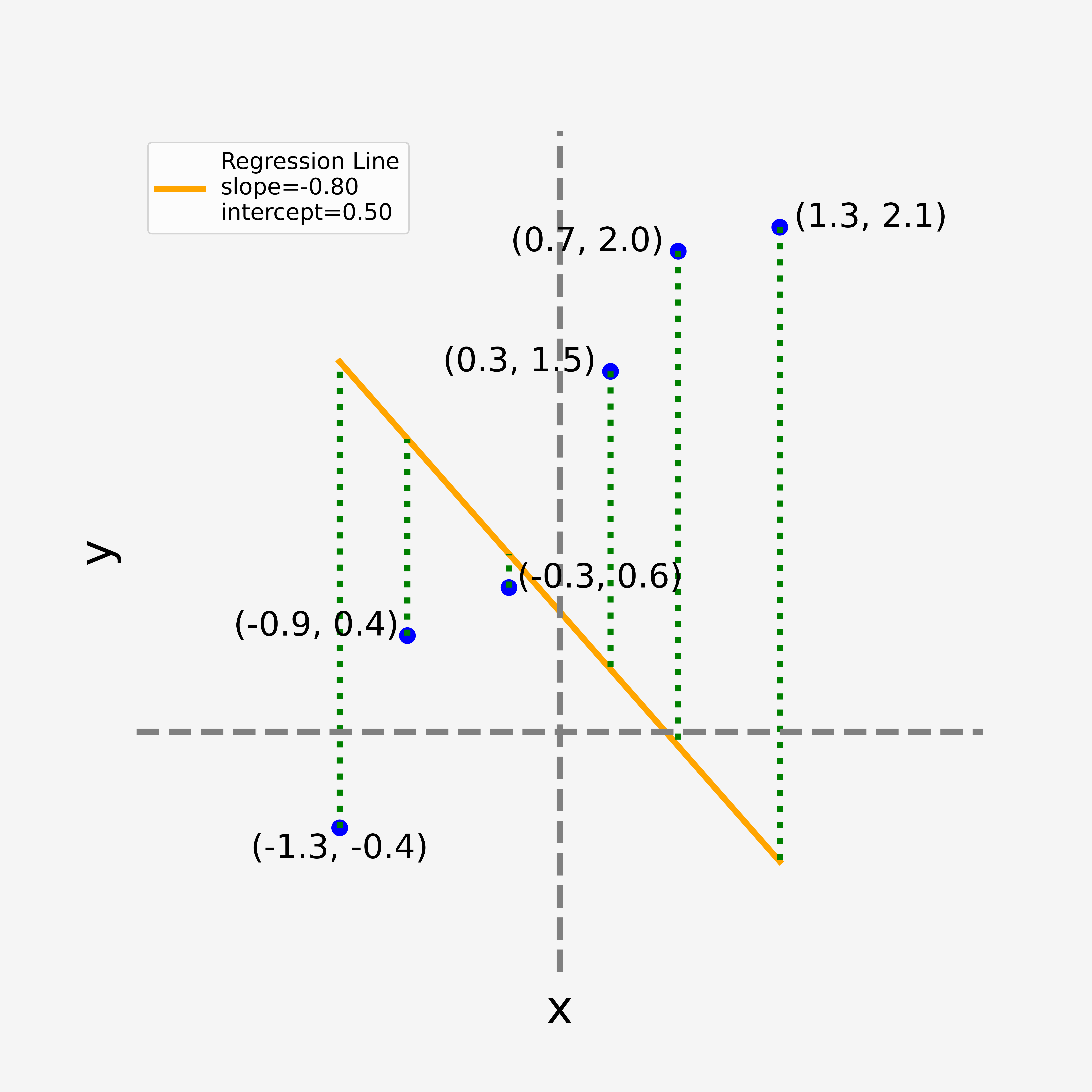
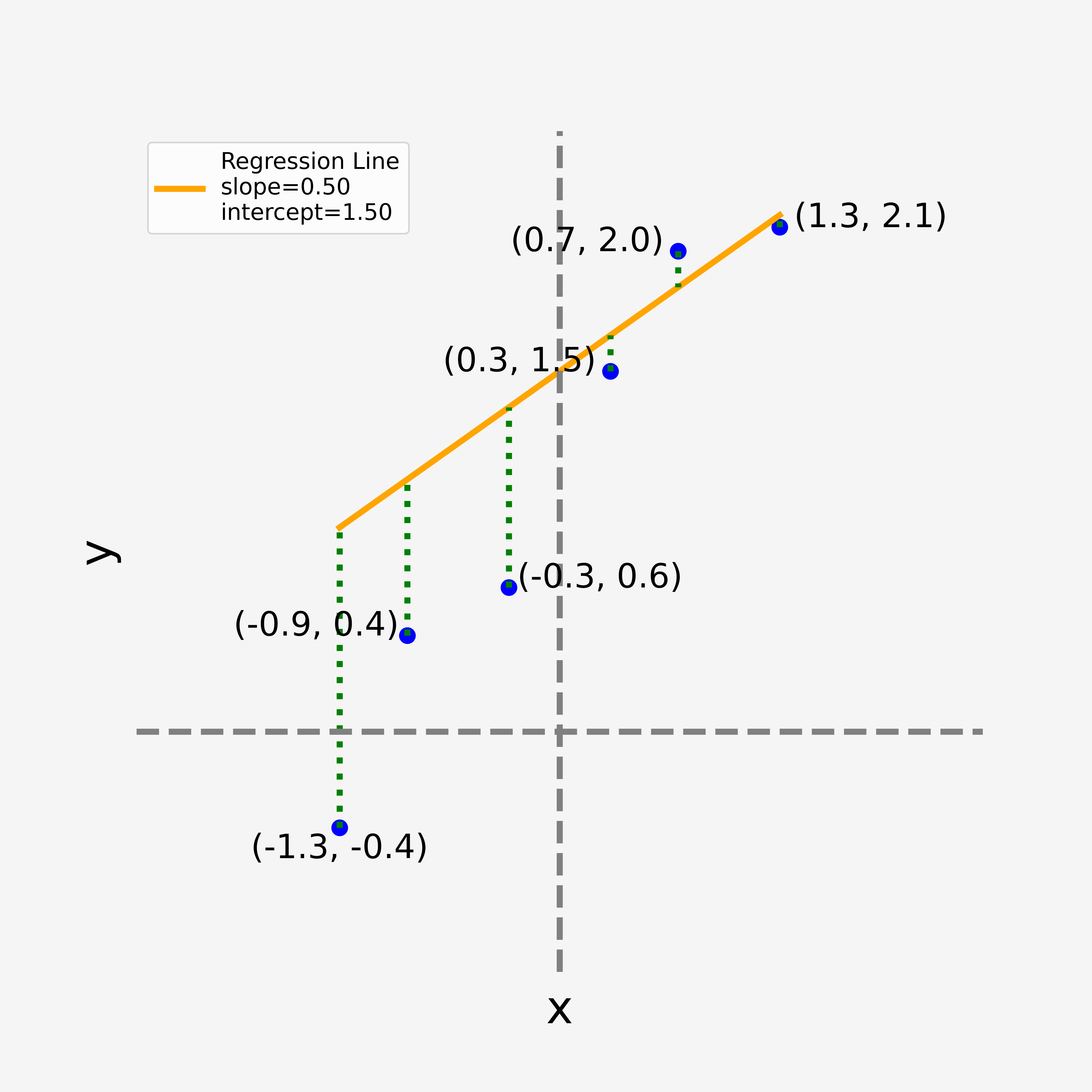
One typically defines the “best fit” as being the line that minimizes the combined area of the squares that fit between each data point and the straight line function. That is, imagine that those dashed green lines are the edge of an associated square area; we look to minimize the sum of those square areas.
Those green lines are referred to as the residuals. The residual for each data point can be represented by the equation
where the “hat” symbol in
So now, consider once again the four plots shown above. These represent four different specifications of:
with
And therefore the matrix representation for our model can be specified based on the above discussion, in the following manner:
- Each residual
can be stacked into a column vector . - Likewise, the true value for the data point (
it’s y-coordinate), can also be represented as a column vector; . - For the representation of our fitted line, i.e. our model
, we note how these terms can be represented by the matrix-vector multiplication . Here, the vector represents our estimates for the parameters and , while the matrix specifies our independent variable. Finally, I draw your attention to the column vector in order to ensure the parameter is appropriately specified for each data point.
Notice how much using linear algebra simplifies the notation.
Principal Component Analysis
Todo